 Engineering
Engineering
Openshift Series - Chương 1: Làm quen với Openshift

Nội dung chương này bao gồm:
- Các nền tảng container đang thay đổi ngành CNTT như thế nào?
- So sánh container với máy ảo
- Hiểu khi nào container không phải là giải pháp phù hợp
- Thiết kế của OpenShift
Container đang thay đổi phương thức làm việc trong ngành CNTT. Ban đầu, container xuất hiện trên máy tính xách tay của các lập trình viên, giúp họ phát triển ứng dụng nhanh hơn so với việc sử dụng máy ảo hoặc cấu hình trực tiếp trên hệ điều hành. Khi container ngày càng phổ biến trong môi trường phát triển, phạm vi ứng dụng của chúng cũng mở rộng. Từ việc chỉ giới hạn trên laptop và các phòng lab phát triển nhỏ, container đã nhanh chóng được áp dụng trong môi trường doanh nghiệp. Chỉ trong vài năm, container đã phát triển đến mức có thể vận hành các workload sản xuất quy mô lớn như GitHub (www.github.com).
LƯU Ý: Sự thành công của Pokémon GO chạy trên nền tảng container là một câu chuyện thú vị. Pokémon GO chạy trên Google Cloud Platform. Các workload khổng lồ của nó được ghi lại trong bài blog “Đưa Pokémon GO vào cuộc sống trên Google Cloud” của Luke Stone (29/09/2016, http://mng.bz/dK8B). Lần tới khi bạn đang rình bắt một con Pikachu trong công viên, hãy nhớ rằng tất cả những điều đó đang diễn ra trong một container.
1.1 Nền tảng container là gì?
1.1.1. Container trong OpenShift
Một container runtime (trình chạy container) với các version trước đây (v3.x) sử dụng Docker còn hiện tại (OpenShift 4.x+) sử dụng CRI-O hoạt động trên máy chủ Linux để tạo và quản lý các container. Để hiểu rõ hơn, chúng ta cần tìm hiểu cách container vận hành trên hệ thống Linux.
Trong các chương tiếp theo, chúng ta sẽ đi sâu vào cách container cô lập các ứng dụng trong OpenShift. Trước hết, bạn có thể xem container như những đơn vị độc lập, linh động và có khả năng mở rộng dành cho các ứng dụng.
Container chứa tất cả những thứ cần thiết để ứng dụng bên trong hoạt động. Khi được triển khai, mỗi container đều bao gồm đầy đủ thư viện và mã nguồn để ứng dụng có thể chạy đúng cách (xem hình 1.1).
Các ứng dụng trong container chỉ có thể truy cập tài nguyên nội bộ của container đó. Chúng hoàn toàn được cô lập khỏi mọi thứ đang chạy trong các container khác hoặc trên máy chủ (host). Có năm loại tài nguyên được cô lập với container:
- Các hệ thống tệp (filesystem) được mount: Mounted filesystems
- Tài nguyên bộ nhớ chia sẻ: Shared memory resources
- Tên máy chủ (hostname) và tên miền (domain name): Hostname and domain name
- Tài nguyên mạng (địa chỉ IP, địa chỉ MAC, bộ đệm bộ nhớ): Network resources (IP address, MAC address, memory buffers)
- Bộ đếm tiến trình (process): Process counters
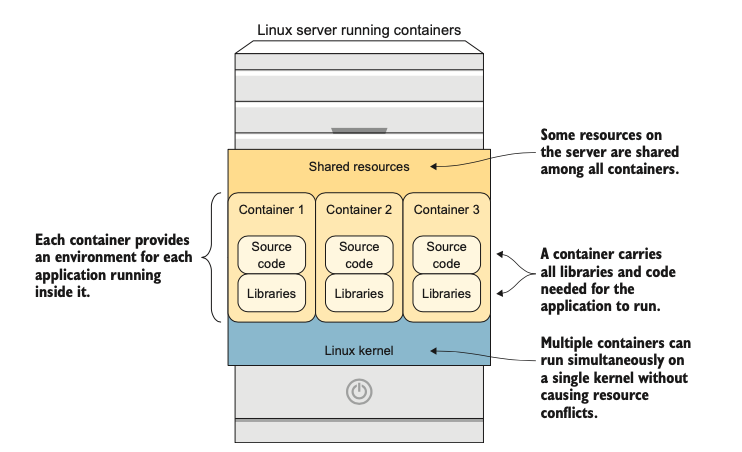
Hình 1.1: Tổng quan về các thuộc tính của container
đều là một phần của nhân Linux. Các tài nguyên này bao gồm những thứ như SELinux, các không gian tên (namespaces) của Linux, và các nhóm điều khiển (control groups - cgroups), tất cả sẽ được đề cập.Ngoài việc làm cho việc sử dụng các tài nguyên này dễ dàng hơn nhiều, docker còn bổ sung một số tính năng đã nâng cao sự phổ biến và phát triển của nó:
- Tính di động (Portability)—Khác với các định dạng container trước đây không thể di chuyển giữa các hệ điều hành, định dạng container hiện nay đã được chuẩn hóa thông qua Open Container Initiative.¹
- Tái sử dụng Image (Image reuse)—Mọi image container đều có thể được dùng làm nền tảng để tạo các image container mới.
- API lấy ứng dụng làm trung tâm (Application-centric API)—Hệ thống API và công cụ dòng lệnh giúp lập trình viên dễ dàng tạo, cập nhật và xóa container.
- Hệ sinh thái (Ecosystem)—Docker, Inc. cung cấp một kho lưu trữ công cộng miễn phí cho image container, hiện đang chứa hàng trăm nghìn image.
1.1.2. Điều phối (Orchestrating) container
Để điều phối container hiệu quả trên nhiều máy chủ, bạn cần một công cụ điều phối container (container orchestration engine). Đây là ứng dụng quản lý container runtime trên cụm máy chủ, nhằm cung cấp nền tảng ứng dụng có khả năng mở rộng. OpenShift sử dụng Kubernetes (https://kubernetes.io) làm công cụ điều phối container.
Kubernetes là dự án mã nguồn mở do Google khởi xướng và đến năm 2015 được chuyển giao cho Cloud Native Computing Foundation (www.cncf.io).
Kubernetes sử dụng kiến trúc master/node. Các máy chủ master của Kubernetes duy trì thông tin về cụm máy chủ, và các node chạy các workload ứng dụng thực tế (xem hình 1.2).
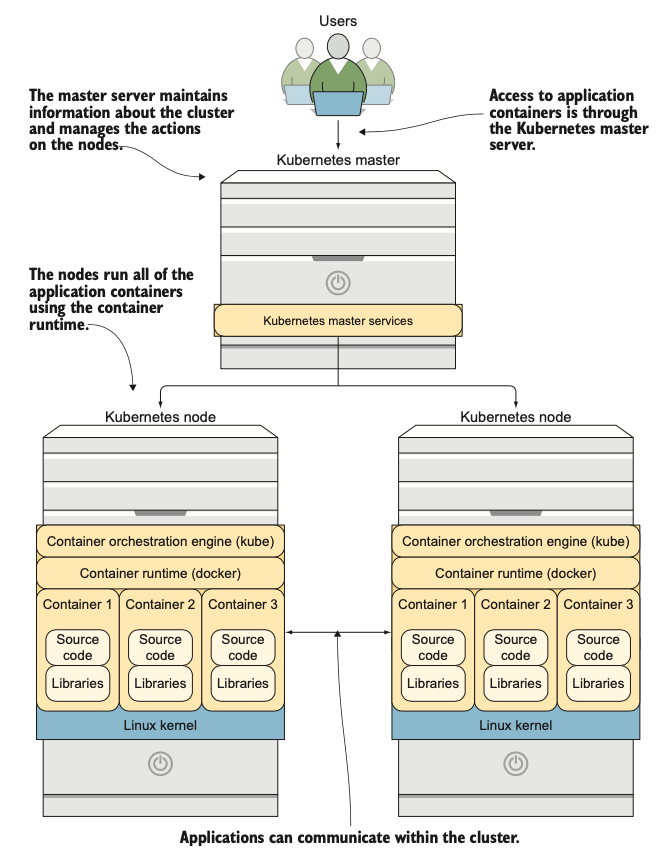
Hình 1.2: Tổng quan về kiến trúc Kubernetes
1.2. Tìm hiểu về kiến trúc
OpenShift sử dụng kiến trúc master/node của Kubernetes làm điểm xuất phát. Từ đó, nó mở rộng để cung cấp các dịch vụ bổ sung mà một nền tảng ứng dụng tốt cần có sẵn.
1.2.1. Tích hợp image container
Trong một nền tảng container như OpenShift, các image container được tạo khi triển khai hoặc cập nhật ứng dụng. Để đảm bảo hiệu quả, các image container cần phải sẵn sàng nhanh chóng trên mọi node ứng dụng trong cụm. Vì vậy, OpenShift tích hợp sẵn một image registry tích hợp như một phần của cấu hình mặc định (hình 1.3).
Image registry là một kho lưu trữ trung tâm có khả năng phân phối các image container đến nhiều địa điểm khác nhau. Trong OpenShift, registry tích hợp này hoạt động dưới dạng một container.
1.2.2. Truy cập ứng dụng
Trong Kubernetes, các container được tạo trên các node thông qua các thành phần gọi là pod. Khi một ứng dụng có nhiều pod, việc truy cập được quản lý qua một thành phần gọi là service.
Service đóng vai trò như một proxy, kết nối nhiều pod và ánh xạ chúng tới một địa chỉ IP trên một hoặc nhiều node trong cụm.
Tuy nhiên, địa chỉ IP thường khó quản lý và chia sẻ, đặc biệt khi nằm sau tường lửa. OpenShift giải quyết vấn đề này bằng lớp định tuyến (routing layer) tích hợp—một bộ cân bằng tải (load balancer) phần mềm. Khi triển khai ứng dụng trên OpenShift, hệ thống tự động tạo bản ghi DNS cho ứng dụng đó. Bản ghi này được thêm vào bộ cân bằng tải, cho phép bộ cân bằng tải giao tiếp với service của Kubernetes để xử lý hiệu quả các kết nối giữa ứng dụng và người dùng (xem hình 1.3).
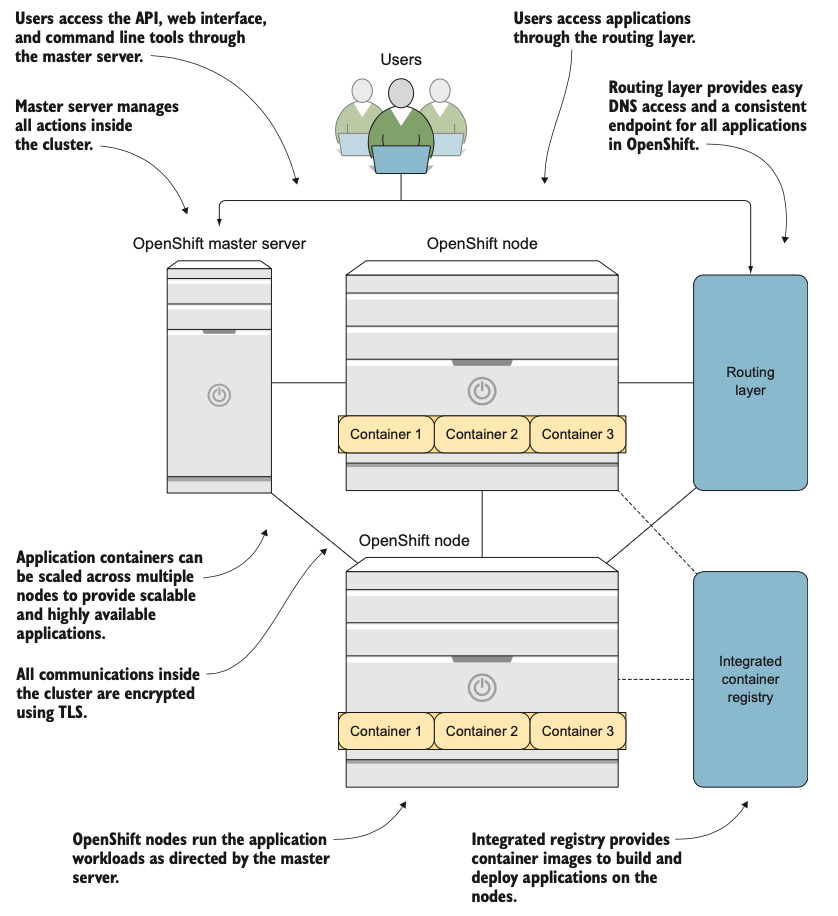
Hình 1.3: Tổng quan về kiến trúc của OpenShift
1.2.3. Xử lý lưu lượng mạng trong cụm
OpenShift sử dụng một giải pháp mạng bằng phần mềm (Software-Defined Networking - SDN) để mã hóa và định hình lưu lượng mạng trong một cụm. OpenShift SDN, một giải pháp SDN sử dụng Open vSwitch (OVS, http://openvswitch.org) và Kubernetes OVN và các công nghệ mã nguồn mở khác, được cấu hình mặc định khi OpenShift được triển khai.
Bây giờ bạn đã có một ý tưởng tốt về cách OpenShift được thiết kế, hãy cùng xem vòng đời của một ứng dụng trong cụm OpenShift.
1.3. Tìm hiểu về một ứng dụng
OpenShift có các luồng công việc được thiết kế để giúp bạn quản lý các ứng dụng của mình qua tất cả các giai đoạn của vòng đời:
- Build (Xây dựng)
- Deploy (Triển khai)
- Upgrade (Nâng cấp)
- Retirement (Loại bỏ)
1.3.1. Xây dựng ứng dụng
Cách chính để xây dựng ứng dụng là sử dụng một builder image.
Một builder image là một image container đặc biệt bao gồm các ứng dụng và thư viện cần thiết cho một ứng dụng trong một ngôn ngữ nhất định. Quá trình build lấy mã nguồn của một ứng dụng và kết hợp nó với builder image để tạo ra một custom application image(image ứng dụng tùy chỉnh) cho ứng dụng đó. Image ứng dụng tùy chỉnh được lưu trữ trong registry tích hợp (xem hình 1.4), nơi nó sẵn sàng để được triển khai và phục vụ người dùng của ứng dụng.
1.3.2. Triển khai và phục vụ ứng dụng
Việc triển khai ứng dụng được kích hoạt tự động sau khi image container được xây dựng và có sẵn. Quá trình triển khai lấy image ứng dụng mới tạo và triển khai nó trên một hoặc nhiều node. Ngoài các pod ứng dụng, một service cũng được tạo ra, cùng với một route DNS trong lớp định tuyến.
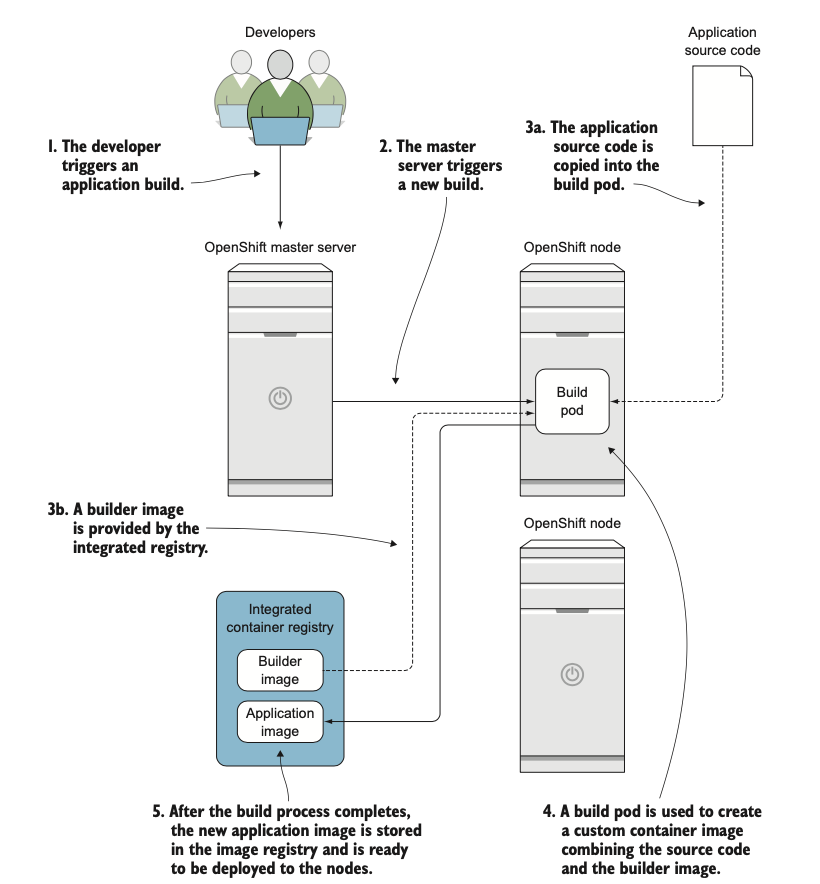
Hình 1.4: Tổng quan về quy trình build ứng dụng.
Người dùng có thể truy cập ứng dụng mới tạo thông qua lớp định tuyến sau khi tất cả các thành phần đã được triển khai (xem hình 1.5).
Việc nâng cấp ứng dụng sử dụng cùng một luồng công việc. Khi một nâng cấp được kích hoạt, một image container mới được tạo ra, và phiên bản ứng dụng mới được triển khai. Có nhiều quy trình nâng cấp khác nhau; chúng ta sẽ thảo luận sâu hơn về chúng trong chương 6.
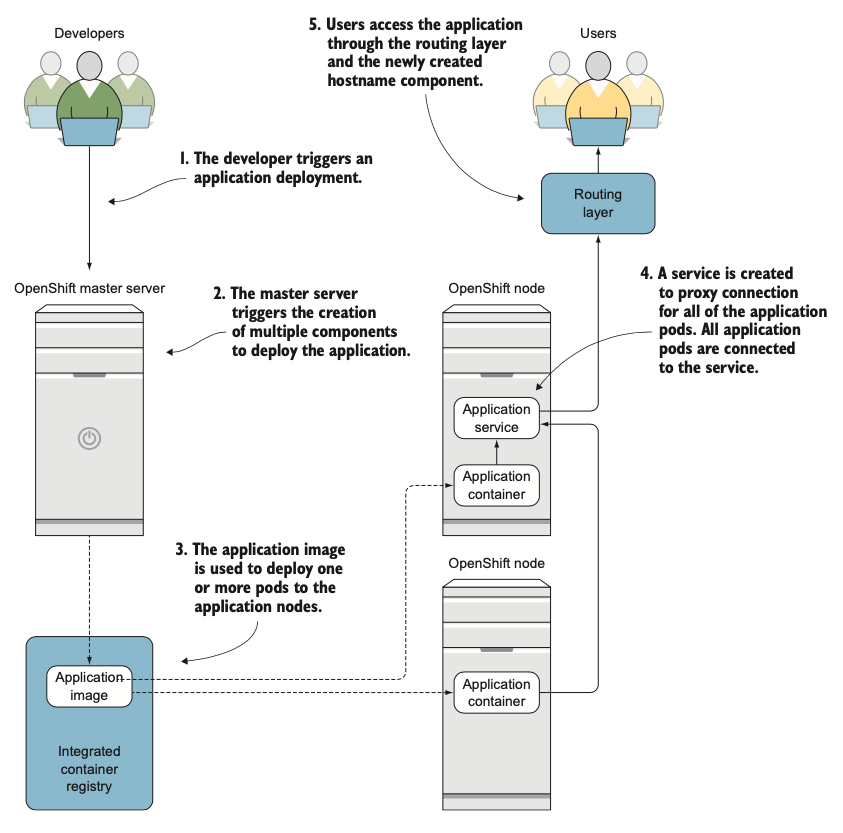
Hình 1.5: Tổng quan về việc triển khai ứng dụng.
1.4 Các trường hợp sử dụng cho nền tảng container
1.4.1. Các trường hợp sử dụng về công nghệ
Bắt đầu từ máy tính lớn (mainframe), chúng ta đã có thể cô lập các ứng dụng hiệu quả hơn với mô hình client-server và cuộc cách mạng x86. Theo sau đó là cuộc cách mạng ảo hóa. Nhiều máy ảo có thể chạy trên một máy chủ vật lý duy nhất. Điều này mang lại cho các quản trị viên mật độ tốt hơn trong các trung tâm dữ liệu của họ trong khi vẫn cô lập các tiến trình khỏi nhau.
Với máy ảo, mỗi tiến trình được cô lập trong máy ảo riêng của nó. Bởi vì mỗi máy ảo có một hệ điều hành và một nhân (kernel) đầy đủ (xem hình 1.6), nó phải có tất cả các hệ thống tệp cần thiết cho một hệ điều hành đầy đủ. Điều đó cũng có nghĩa là nó phải được vá lỗi, quản lý và đối xử như cơ sở hạ tầng truyền thống.
Container là bước tiếp theo trong quá trình tiến hóa này. Một container ứng dụng chứa mọi thứ mà ứng dụng cần để chạy:
- Mã nguồn hoặc mã đã được biên dịch của ứng dụng
- Các thư viện hoặc ứng dụng cần thiết để ứng dụng hoạt động đúng cách
- Các cấu hình và thông tin về việc kết nối với các nguồn dữ liệu chia sẻ
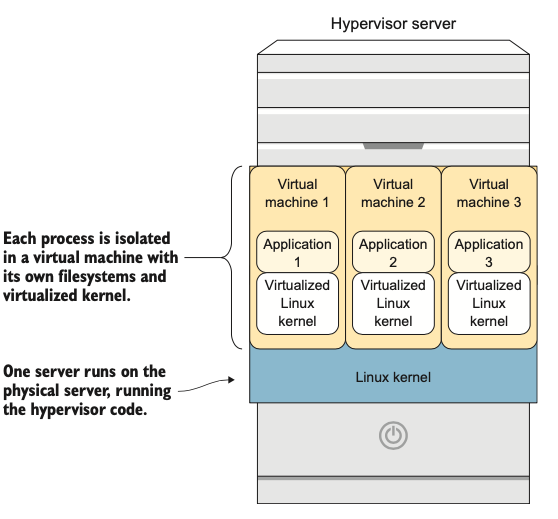
Hình 1.6: Máy ảo có thể được sử dụng để cô lập tiến trình.
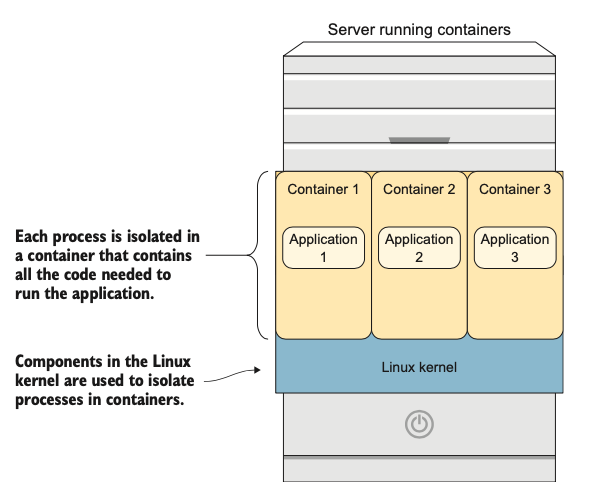
Hình 1.7: Container sử dụng một nhân duy nhất để phục vụ các ứng dụng, tiết kiệm không gian và tài nguyên, đồng thời cung cấp các nền tảng ứng dụng linh hoạt
Không giống như máy ảo, tất cả các container đều chạy trên một nhân Linux duy nhất, được chia sẻ. Container không cần phải bao gồm một nhân đầy đủ để phục vụ ứng dụng của chúng, cùng với tất cả các phụ thuộc của một hệ điều hành, chúng có xu hướng nhỏ hơn nhiều so với máy ảo cả về nhu cầu lưu trữ và tiêu thụ tài nguyên. Ví dụ, trong khi một máy ảo điển hình bắt đầu với một đĩa 10 GB hoặc lớn hơn, image container CentOS 7 chỉ có dung lượng 140 MB.
Việc nhỏ hơn mang lại một vài lợi thế. Đầu tiên, tính di động được tăng cường. Di chuyển 140 MB từ máy chủ này sang máy chủ khác nhanh hơn nhiều so với việc di chuyển 10 GB hoặc hơn.
Thứ hai, vì việc khởi động một container không bao gồm việc khởi động toàn bộ một nhân, quá trình khởi động nhanh hơn nhiều. Việc khởi động một container thường được đo bằng mili giây, so với giây hoặc phút đối với máy ảo.
1.4.2. Các trường hợp sử dụng cho doanh nghiệp
SỬ DỤNG TÀI NGUYÊN HIỆU QUẢ HƠN VỚI CONTAINER
Nếu bạn so sánh một máy chủ sử dụng máy ảo để cô lập các tiến trình với một máy chủ sử dụng container để làm điều tương tự, bạn sẽ nhận thấy một vài khác biệt chính (xem hình 1.8):
- Container tiêu thụ tài nguyên máy chủ hiệu quả hơn. Bởi vì chỉ có một nhân được chia sẻ cho tất cả các container trên một máy chủ, thay vì nhiều nhân ảo hóa như trong máy ảo, nhiều tài nguyên của máy chủ được sử dụng để phục vụ các ứng dụng thay vì cho chi phí hoạt động của nền tảng.
- Mật độ ứng dụng tăng lên với container. Bởi vì đơn vị cơ bản được sử dụng để triển khai các ứng dụng (image container) nhỏ hơn nhiều so với đơn vị cho máy ảo (image máy ảo), nhiều ứng dụng hơn có thể vừa trên mỗi máy chủ. Điều này có nghĩa là nhiều ứng dụng hơn yêu cầu ít máy chủ hơn để chạy.
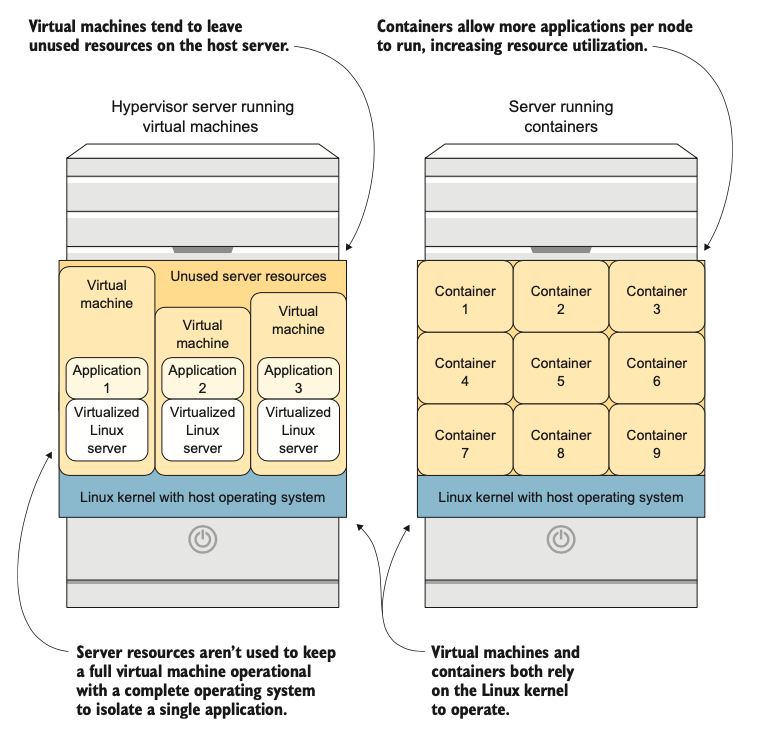
Hình 1.8: So sánh máy ảo và container: container cung cấp việc sử dụng tài nguyên máy chủ tốt hơn.
1.4.3. Khi nào container không phải là giải pháp
KHI LỢI TỨC ĐẦU TƯ (ROI) QUÁ THẤP
Nếu bạn có một ứng dụng kế thừa (legacy) phức tạp, hãy cẩn thận khi quyết định chia nhỏ nó và chuyển đổi thành một loạt các container. Nếu một ứng dụng sẽ tồn tại trong 18 tháng, và sẽ mất 9 tháng làm việc để container hóa nó đúng cách, bạn có thể muốn để nó ở nguyên vị trí. Không sao đâu, chúng tôi hứa.
KHI BẠN CẦN TRUY CẬP VÀO PHẦN CỨNG ĐẶC BIỆT
Các giải pháp container bắt đầu trong thế giới CNTT doanh nghiệp. Chúng được thiết kế để hoạt động với hầu hết các giải pháp lưu trữ và mạng cấp doanh nghiệp, nhưng chúng không hoạt động dễ dàng với tất cả chúng. Khi bạn đang sử dụng một giải pháp mạng như InfiniBand, hoặc một giải pháp lưu trữ như Lustre, container có thể là một thách thức.
KHI CÁC ỨNG DỤNG NGUYÊN KHỐI CỦA BẠN SẼ LUÔN LÀ NGUYÊN KHỐI
Một số ứng dụng sẽ luôn là các ứng dụng nguyên khối (monolithic) rất lớn, tiêu tốn nhiều tài nguyên. Ví dụ là phần mềm dùng để chạy các phòng ban nhân sự và một số cơ sở dữ liệu quan hệ rất lớn. Nếu một ứng dụng duy nhất sẽ chiếm nhiều máy chủ, việc chạy nó trong một container muốn chia sẻ tài nguyên với các ứng dụng khác trên một máy chủ không có nhiều ý nghĩa.
1.5 Giải quyết nhu cầu lưu trữ của container
Container là một công nghệ mang tính cách mạng, nhưng chúng không thể tự làm mọi thứ. Lưu trữ là một lĩnh vực mà container cần được kết hợp với một giải pháp khác để triển khai các ứng dụng sẵn sàng cho sản xuất.
Điều này là do bộ nhớ được tạo ra khi một container được triển khai là ephemeral (tạm thời). Nếu một container bị phá hủy hoặc thay thế, bộ nhớ từ bên trong container đó sẽ không được tái sử dụng.
Điều này là do thiết kế, để cho phép các container mặc định là stateless (không trạng thái). Nếu có sự cố, một container có thể được gỡ bỏ hoàn toàn khỏi môi trường của bạn, và một container mới có thể được tạo ra để thay thế nó gần như ngay lập tức.
Ý tưởng về một container ứng dụng stateless rất tuyệt vời. Nhưng ở đâu đó trong ứng dụng của bạn, thường là ở nhiều nơi, dữ liệu cần được chia sẻ qua nhiều container, và trạng thái cần được bảo tồn. Dưới đây là một số ví dụ về các tình huống này:
- Dữ liệu được chia sẻ cần có sẵn cho nhiều container, như các hình ảnh được tải lên cho một ứng dụng web
- Thông tin trạng thái người dùng trong một ứng dụng phức tạp, cho phép người dùng tiếp tục từ nơi họ đã dừng lại trong một giao dịch kéo dài
-
Thông tin được lưu trữ trong các cơ sở dữ liệu quan hệ hoặc phi quan hệ
Trong tất cả các tình huống này, và nhiều tình huống khác, bạn cần có lưu trữ bền vững (persistent storage) có sẵn trong các container của mình. Bộ nhớ này nên được định nghĩa như một phần của việc triển khai ứng dụng của bạn và nên có sẵn từ tất cả các node trong cụm OpenShift của bạn. May mắn thay, OpenShift có nhiều cách để giải quyết vấn đề này.
Trong chương 7, bạn sẽ cấu hình một dịch vụ lưu trữ mạng bên ngoài. Sau đó, bạn sẽ cấu hình nó để tương tác với OpenShift để các ứng dụng có thể tự động phân bổ và tận dụng các persistent storage volume (volume lưu trữ bền vững) của nó (xem hình 1.9).
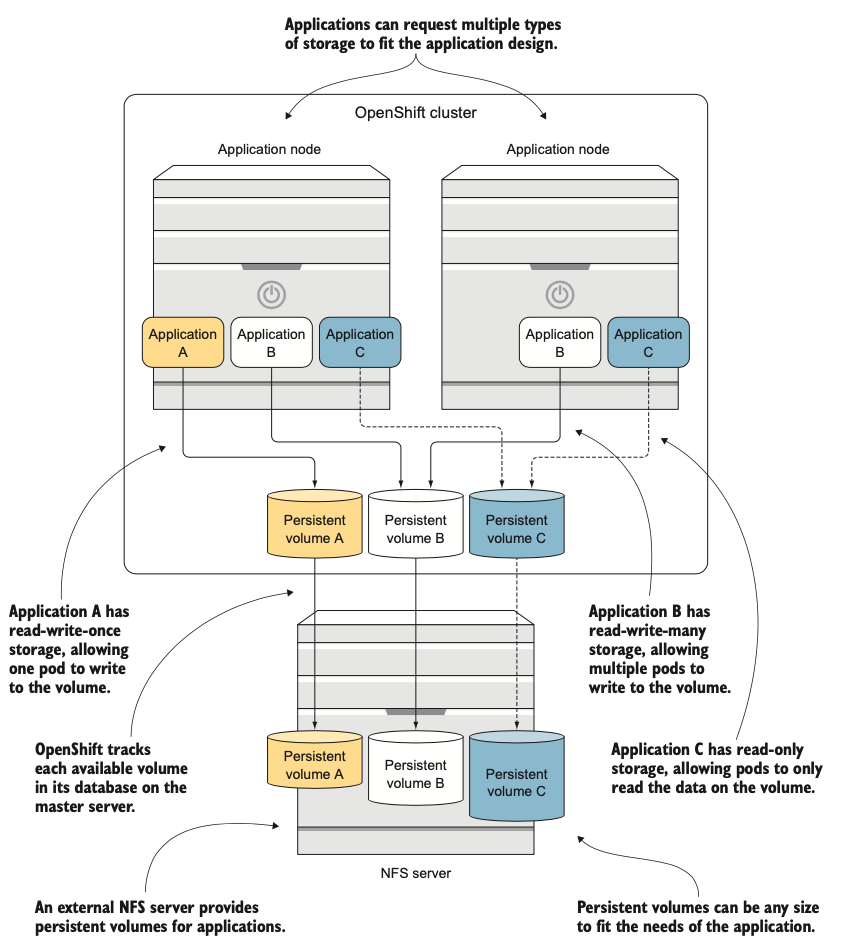
Hình 1.9: OpenShift có thể tích hợp và quản lý các nền tảng lưu trữ bên ngoài và đảm bảo volume lưu trữ phù hợp nhất được khớp với các ứng dụng cần nó.
1.6. Mở rộng (Scaling) ứng dụng
Đối với các ứng dụng stateless, việc mở rộng quy mô lên và xuống rất đơn giản. Bởi vì không có phụ thuộc nào khác ngoài những gì có trong container ứng dụng, và bởi vì các giao dịch xảy ra trong container được thiết kế là nguyên tử (atomic), tất cả những gì bạn cần làm để mở rộng một ứng dụng stateless là triển khai thêm các phiên bản của nó và cân bằng tải chúng với nhau.
Để làm cho quá trình này dễ dàng hơn nữa, OpenShift proxy các kết nối đến mỗi ứng dụng thông qua một bộ cân bằng tải tích hợp. Điều này cho phép các ứng dụng mở rộng quy mô lên và xuống mà không có thay đổi nào về cách người dùng kết nối với ứng dụng.
Nếu các ứng dụng của bạn là stateful, nghĩa là chúng cần lưu trữ hoặc truy xuất dữ liệu chia sẻ, chẳng hạn như một cơ sở dữ liệu hoặc dữ liệu mà người dùng đã tải lên, thì bạn cần có khả năng cung cấp lưu trữ bền vững cho chúng. Bộ nhớ này cần tự động mở rộng quy mô lên và xuống cùng với các ứng dụng của bạn trong OpenShift. Đối với các ứng dụng stateful, lưu trữ bền vững là một thành phần quan trọng phải được tích hợp chặt chẽ vào thiết kế của bạn. Cuối cùng, các pod stateful là cách người dùng sẽ lấy dữ liệu vào và ra khỏi ứng dụng của bạn.
1.7. Tích hợp ứng dụng stateful và stateless
Khi bạn bắt đầu tách các ứng dụng nguyên khối, truyền thống thành các dịch vụ nhỏ hơn hoạt động hiệu quả trong container, bạn sẽ bắt đầu nhìn nhận nhu cầu dữ liệu của mình theo một cách khác. Quá trình này thường được gọi là thiết kế ứng dụng dưới dạng microservices.
Đối với bất kỳ ứng dụng nào, bạn sẽ có các dịch vụ cần phải là stateful, và những dịch vụ khác là stateless. Ví dụ, dịch vụ cung cấp nội dung web tĩnh có thể là stateless, trong khi dịch vụ xử lý xác thực người dùng cần có khả năng ghi thông tin vào bộ nhớ bền vững. Tất cả các dịch vụ này kết hợp với nhau để tạo thành ứng dụng của bạn.
Bởi vì mỗi dịch vụ chạy trong container riêng của nó, các dịch vụ có thể được mở rộng quy mô lên và xuống một cách độc lập. Thay vì phải mở rộng toàn bộ cơ sở mã của bạn, với container bạn chỉ cần mở rộng các dịch vụ trong ứng dụng của mình cần xử lý các workload bổ sung.
Ngoài ra, bởi vì chỉ những container cần truy cập vào bộ nhớ bền vững mới của nó, dữ liệu đi vào container của bạn sẽ an toàn hơn. Trong hình 1.10, nếu có một lỗ hổng trong dịch vụ B, một tiến trình bị xâm nhập sẽ khó có thể truy cập vào dữ liệu được lưu trữ trong bộ nhớ bền vững.
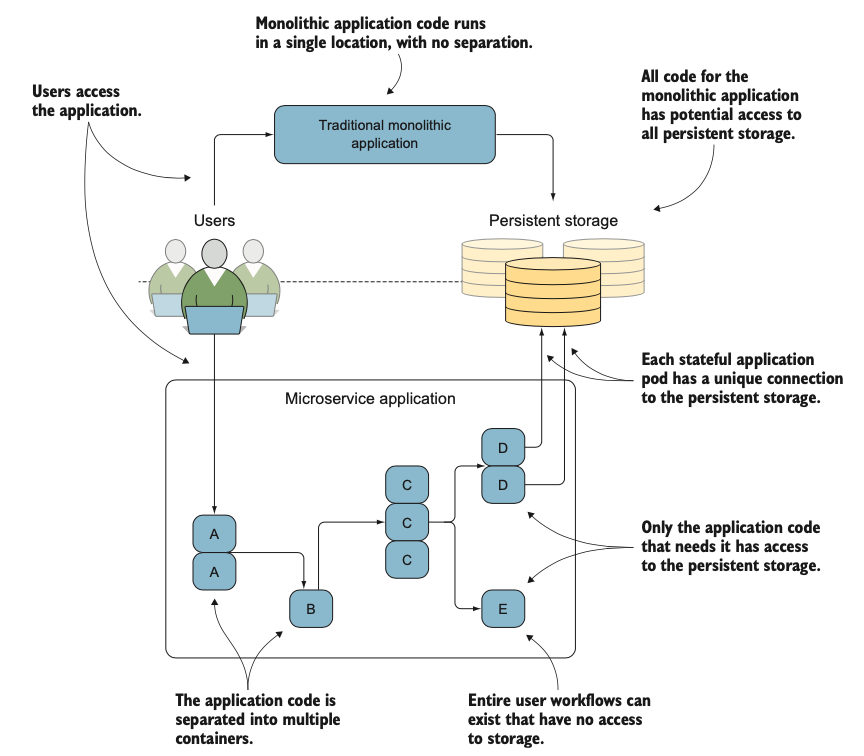
Hình 1.10: Minh họa sự khác biệt giữa các ứng dụng truyền thống và microservices: các ứng dụng microservices mở rộng các thành phần của chúng một cách độc lập, tạo ra hiệu suất và việc sử dụng tài nguyên tốt hơn.
1.8. Tóm tắt
Điều đó đưa chúng ta đến cuối phần giới thiệu ban đầu về OpenShift và cách nó triển khai, quản lý và điều phối các ứng dụng được triển khai bằng container sử dụng docker và Kubernetes. Những lợi ích do OpenShift cung cấp giúp tiết kiệm thời gian cho con người và sử dụng tài nguyên máy chủ hiệu quả hơn. Ngoài ra, bản chất của cách container hoạt động cung cấp khả năng mở rộng và tốc độ triển khai được cải thiện so với việc triển khai máy ảo.
Tất cả những điều này kết hợp lại để cung cấp một nền tảng ứng dụng cực kỳ mạnh mẽ mà bạn sẽ làm việc cùng trong phần còn lại của Series này. Trong chương 2, bạn sẽ cài đặt và cấu hình OpenShift, và triển khai các ứng dụng đầu tiên của mình.
- OpenShift là một nền tảng ứng dụng sử dụng docker, Kubernetes và các dịch vụ bổ sung để triển khai các ứng dụng.
- Docker là một container runtime tạo và quản lý các container trên một máy chủ duy nhất.
- Kubernetes là một công cụ điều phối container được sử dụng để điều phối các workload của container engine trên nhiều máy chủ trong một cụm.
- OpenShift mở rộng trên thiết kế của Kubernetes, bổ sung các thành phần quan trọng có sẵn.
- Container cung cấp việc sử dụng tài nguyên tốt hơn và khởi động nhanh hơn so với máy ảo.
- Một số tình huống không phải là lựa chọn phù hợp để chạy các ứng dụng trong container.
- OpenShift SDN là một giải pháp SDN mạnh mẽ, có thể cấu hình, được triển khai mặc định trong OpenShift, cùng với một lớp định tuyến ứng dụng và registry image tích hợp.
- Container có thể dễ dàng sử dụng bộ nhớ bền vững trong OpenShift.
- OpenShift có thể kết hợp nhiều ứng dụng stateless và stateful để cung cấp một trải nghiệm ứng dụng duy nhất cho người dùng cuối.
Nguồn tham khảo:
- Red Hat OpenShift Labs: https://learn.openshift.com
- Try OpenShift (cloud): https://console.redhat.com/openshift
- OpenShift in Action – Manning